There are a few generic atproto record viewers out there pdsls.dev, atp.tools, a number of others, anisota.net recently just built one into their webapp), but only really one editor, that being pdsls. It's a good webapp. It's simple and does what it says on the tin, runs entirely client-side. So why an alternative? There's one personal motivation which I'll leave to the wayside, so I'll focus on the UX. Its record editing is exactly what you need. You get a nice little editor window to type or paste or upload JSON into. It has some syntax highlighting. It optionally validates that against a lexicon (determined by the $type NSID, if it can resolve it), gives you a little indicator if it's valid according the the schema, and you can make a new record, or update the current one, or delete it. This is all well and good.
But what if you want to know where a schema violation occurs in the record and what it is? What if you want to add another item to an array where the item schema is big and complex? You can copy-paste text around, but the editor has no notion of the abstract syntax tree of an atproto data model type, it simply gives you a thumbs-up, thumbs-down. And if you want to do something like upload a blob, like an image, you have to figure out how to do that separately and populate all the info manually whoops, it does have that now, missed it in the interface writing the initial version of this. Nothing wrong with that, it all works well and there's lots of clever little convenience features like direct links to the getRecord url and query for a record, constellation backlinks, a really nice OpenAPI-esque lexicon schema display, and so on.
Debugging tools and learning
But regardless, I was frustrated with it, I needed a debugging tool for Weaver records (as I'd already evolved a schema or two in ways that invalidated my own records during testing, which required manual editing), felt the atproto ecosystem deserved a second option for this use case, and I also wanted to exercise some skills before I built the next major part of Weaver, that being the editor.
The first pass at that isn't going to have the collaborative editing I'd like it to have, there's more back-end and protocol work required on that front yet. But I want it to be a nice, solid markdown editor which feels good to use. Specifically, I want it to feel basically like a simpler version of Obsidian's editor, which is what I'm using to compose this. The hybrid compose view it defaults to is perfect for markdown. It will likely have a toolbar rather than rely entirely on key combinations and text input, as I know that that will be useful to people who aren't familiar with Markdown's syntax, but it won't have a preview window, unless you want it to, and it should convey accurately what you're going to get.
That meant I needed to get more familiar with how Dioxus does UI. The notebook entry viewer is basically a very thin UI wrapper around a markdown-to-html converter. The editor can take advantage of that to some degree, but the needs of editing mean it can't just be that plus a text box, not if there's to be a chance in hell of me using it, versus pasting content in from Obsidian, or manually publishing from the CLI. Plus, I have something of a specific aesthetic I'm trying to go for with Weaver, and I wanted more space to refine that vision and explore stylistic choices.
I feel I should clarify that making the record editor use Iosevka mimicking Berkeley Mono as its only font doesn't reflect my vision for the rest of the interface, it just kinda felt right for this specific thing.
So, what should an evolution on a record viewer and editor have? Programmer's text editors and language servers have a lot to teach us here. Your editor should tell you what type a thing is if it's not already obvious. It should show you where an error happened, it should tell you what the error is, and it should help guide you into not making errors, as well as providing convenience features for making common changes.

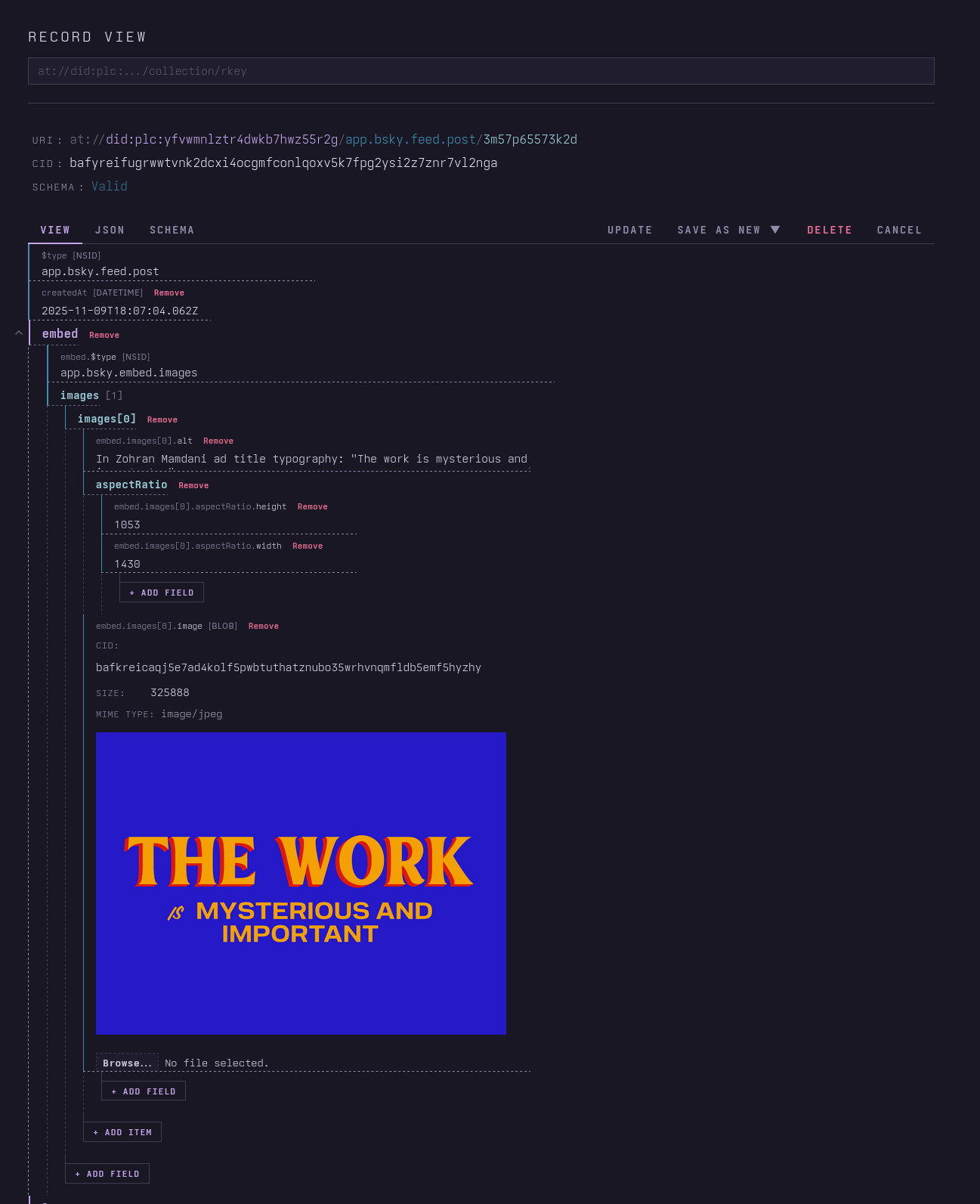
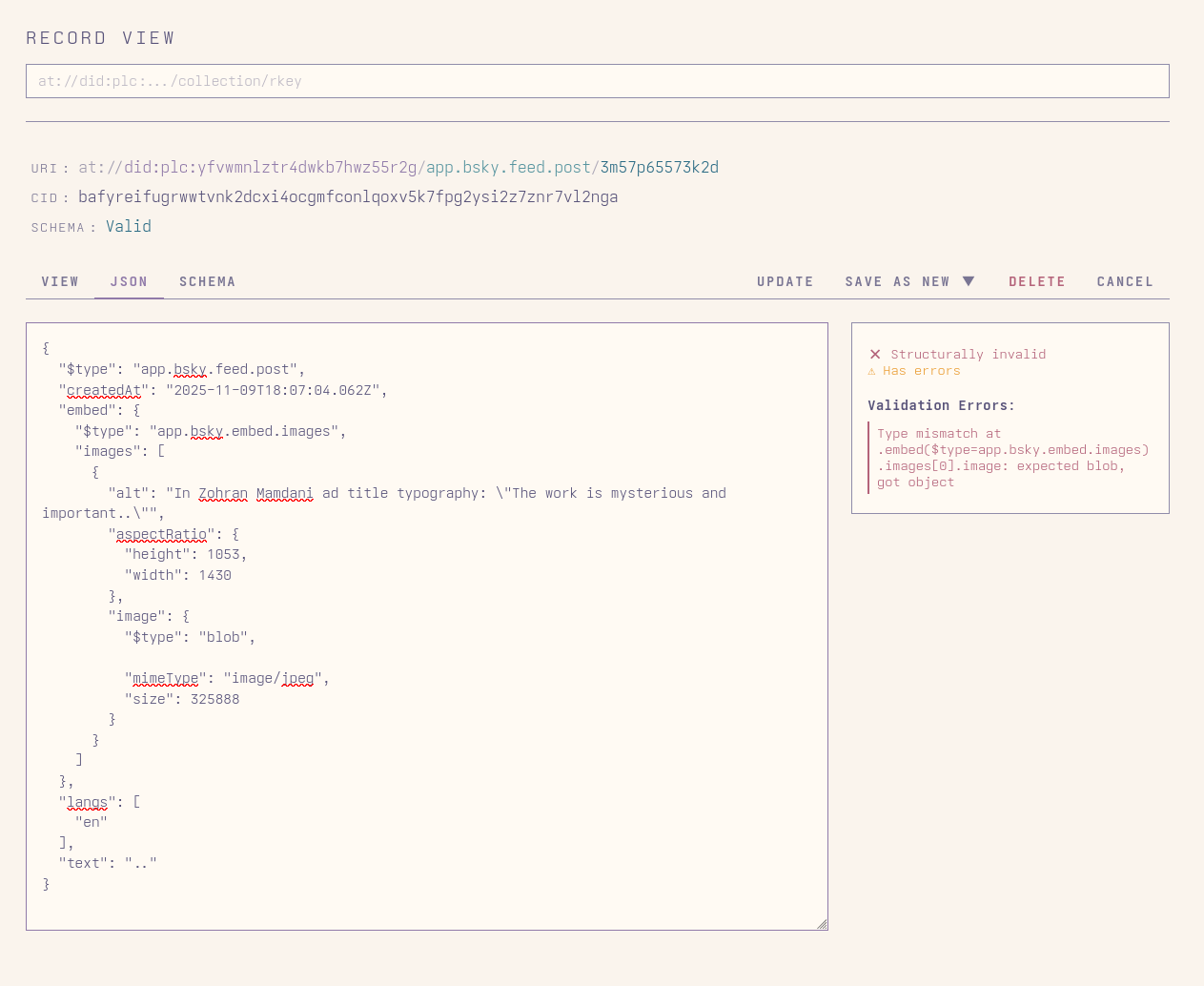
This helps people when they're manually editing, but it also helps people check that what their app is generating is valid, so long as they have a schema we can resolve and validate it against. ATproto apps tend to be pretty permissive when it comes to what they accept and display, as is generally wise, but the above record, for example, breaks Jetstream because whatever tool was used to create it set that empty string $type field, perhaps instead of skipping the embed field for a post with no embeds.
Field-testing Jacquard's features
Another driver behind this was a desire to field-test a number of the unique features of the atproto library I built for Weaver, Jacquard. I've written more about one aspect of its design philosophy and architecture here but since that post I've added a couple pretty powerful features and I needed to give them a shakedown run. One was runtime lexicon resolution and schema validation. The other was the new tools for working with generic atproto data without strong types, like the path query syntax and functions.
For the former, I first had to get lexicon resolution working in WebAssembly, which mean getting DNS resolution working in WebAssembly (the dns feature in jacquard-identity uses hickory-resolver, which only includes support for tokio and async-std runtimes by default, neither of which support wasm32-unknown-unknown, the web wasm target. I went with the DNS over HTTPS route, making calls to Cloudflare's API when the dns feature is disabled for DNS TXT resolution (for both handles and lexicons). At some point I'll make this somewhat more pluggable, so as not to introduce a direct dependency on a specific vendor API, but for the moment this works well.
For the latter, well that's literally what drives the pretty editor. There's a single Data<'static> stored in a Dioxus Signal, which is path-indexed into directly for the field display and for editing.
let string_type = use_memo;
/* --- SNIP --- */
let path_for_mutation = path.clone;
let handle_input = move |evt: | ;
And the path queries are what make the blob upload interface able to do things like auto-populate sibling fields in an image embed, like the aspect ratio.
They also drive the in-situ error display you saw earlier. The lexicon schema validator reports the path of an error in the data, and we can then check that path as we iterate through during the render to know where we should display said error. And yes, I did have to make further improvements to the querying (including adding the mutable reference queries and set_at_path() method to enable editing).
You might also notice the use of the
atproto!{}macro above. This works just like thejson!macro fromserde_jsonand theipld!macro fromipld_core(in fact it's mostly cribbed from the latter). It's been in Jacquard since almost the beginning, but I haven't shown it off much. It's not super well-developed beyond the simple cases, but it works reasonably well and is more compact than building the object manually.
The upshot of all this is that building this meant I discovered a bunch of bugs in my own code, found a bunch of places where my interfaces weren't as nice as they could be, and made some stuff that I'll probably upstream into my own library after testing them in the Weaver web-app (like an abstraction over unauthenticated requests and an authenticated OAuth session, or an OAuth storage implementation using browser LocalStorage, and so on). Working on this also meant that the webapp got enough in it that I felt comfortable doing a bit of a soft-launch of something real under the *.weaver.sh domain.
Amusing meta image
